

決定木 (decision tree) は,色々な条件でデータをふるい分けすることを繰り返し,木のような構造でデータが分類されていく機械学習手法の一種です.
この “ふるい分け” の条件と分けられたデータの経緯が追えるので,なぜその AI モデルが構築されたかといった意味の解釈可能性が高かったり,目的変数に対する説明変数の寄与率が算出できたりするので,比較的非ブラックボックス化できる人に優しい機械学習手法でもあり,データマイニングにも用いられます.
反面,木の深さや構造などの設計値はハイパーパラメータなので,問題に合わせて試行錯誤したり,過学習に注意する必要があります.
オンライン AI コンペの Kaggle などのテーブルデータコンペで良く用いられている XGBoost / lightGBM の基本の部分でもあり,学ぶ価値は十分にあるため,今回は決定木について紹介します.
コードは以下の github にも保存しています.

理論と数式
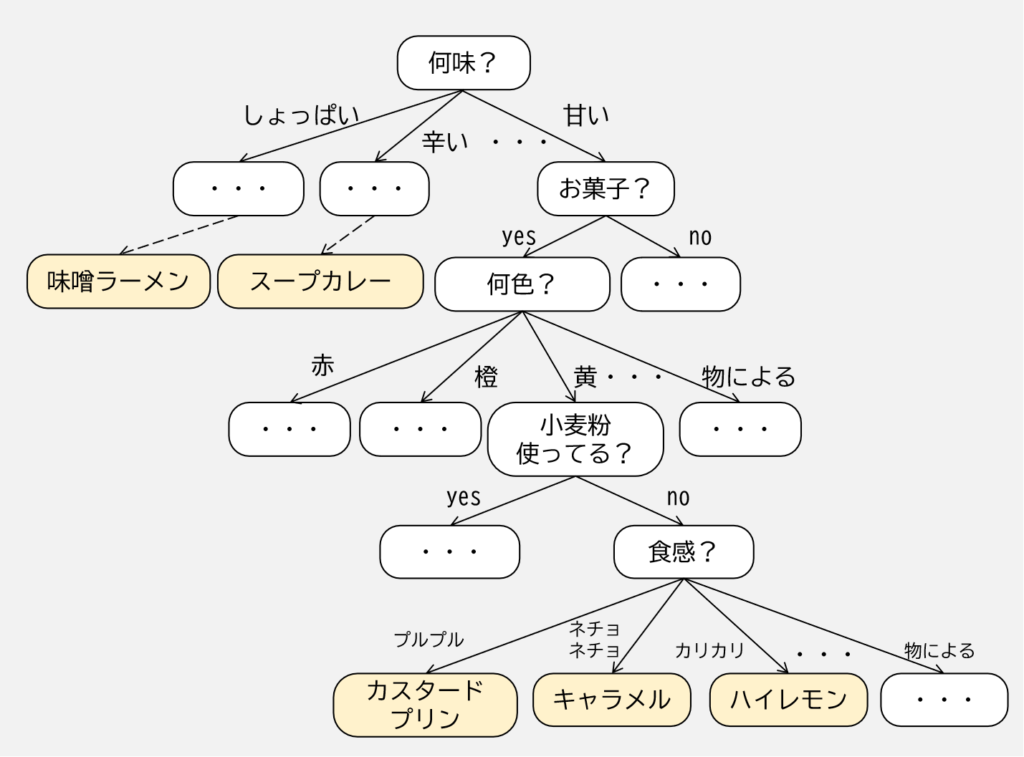
上図のように,決定木では説明変数についていくつかのふるい分け(質問)を学習し,目的変数のラベルを推測するように学習していきます.
例ではクラスラベルを予測していますが,数値などの連続値でも,ふるい分けの条件を例えば「10 以上?」といったものを用いることで回帰問題も扱うことができます.
学習する中身としては,
- 決定木の根(ルート)からスタート
- 分割した集合の要素についてのばらつきの減少を意味する情報利得 (information gain) が最大となる特徴量でデータを分割
- 葉(リーフ)が純粋になる,すなわち,分割されたデータのばらつきの減少がなくなるまで,この分割を子ノード(分岐条件)ごとに繰り返す
という流れです.
リーフが純粋になることは,各リーフの要素が全て同じクラスになることと同義ですが,実際そこまで繰り返し計算を行い木構造を大きくしてしまうと,多くのノードを持った深い木構造になり,結果過学習を起こしやすくなってしまいます.
従って,決定木の最大の深さに上限を設けたり,木構造を剪定 (prune) する必要があります.
では,どうやって情報利得(ゲインと呼ぶのが一般的?)が最大となる特徴量でデータを分割するかということについて,以下で説明していきます.
最大化するにあたって必要な最適化計算で用いる目的関数を次で定義します.
$$
IG(D_p, f) = I(D_p) – \sum_{j=1}^{m} \frac{N_j}{N_p} I (D_j)
$$
ここで,\(f\) は分割を行う特徴量,\(D_p\) は親のデータセット,\(D_j\) は \(j\) 番目の子ノードのデータセット,\(I\) は不純度 (impurity) を数値化したもの,\(N_p\) は親ノードのサンプルの総数,\(N_j\) は \(j\) 番目の子ノードのサンプルの個数を表します.
この数式は,情報利得は「親ノードの不純度」と「子ノードの不順度の合計」の差 のみで定義されることを表しており,子ノードの不順度が小さいほど情報利得は大きくなります.
考え方としては至ってシンプルですね.
先の例や数式では yes / no 疑問文だけでなく複数回答できるような質問とそれの回答としての \(m\) 個のノードを対象としていました.
しかし,探索空間の単純化や計算量低減を目的として,また,scikit-learn を含むほとんどのライブラリは yes / no の分岐だけで構成される二分決定木 (binary decision tree) を採用しているため,これからは二分決定木について説明を行っていきます.
まず,先の式を二分決定木に適応させると,
$$
IG(D_p, f) = I(D_p) – \frac{N_{left}}{N_p} I (D_{left}) – \frac{N_{right}}{N_p} I (D_{right})
$$
となります.
ここで,下付き文字の \(left, right\) は二分決定木で分かれた2つの子ノードに関する変数であることを表しています.
二分決定木における不純度 \(I\) の指標や分割条件は,ジニ不純度 (Gini impurity),エントロピー (entropy),分類誤差 (classification error) が良く使用されます.
以下,ジニ不純度を \(I_G\),エントロピーを \(I_H\),分類誤差を \(I_E\) と記載します.
エントロピーは次式で書き表されます.
$$
I_H(t) = – \sum_{i=1}^{c} p(i|t) \log_2p(i|t)
$$
ここで,\(i\) はクラス,\(t\) はある特定のノード,\(p(i|t)\) は \(t\) において \(i\) に属するサンプルの割合を表します.
ノードのサンプルが全て同じクラスである場合は \(\log_21 = 0\) なのでエントロピーが 0 になります.
エントロピーが最大になるのは,各クラスが一様に分布している場合です.
従って,エントロピーは相互の情報量(2つの確率の相互依存度)が最大化するように試みるような分割条件を与えます.
ジニ不純度は次式で書き表されます.
$$
I_G(t) = – \sum_{i=1}^{c} p(i|t) (1 – p(i|t)) = 1 – \sum_{i=1}^{c} p(i|t)^2
$$
ジニ不純度は,直感的には誤分類の確率を最小化する分割条件を与えます.
エントロピーと同様でジニ不純度が最大になるのはクラスが完全に混合されている場合です.
分類誤差は次式で書き表されます.
$$
I_E(t) = 1 – \max{\left( p(i|t) \right)}
$$
分類誤差については,ノードのクラス確率の変化についてあまり敏感に作用しないため,実際には分割条件として使用されることは少ないです.
コード実装例
今回も機械学習ライブラリの scikit-learn を使います.
決定木は sklearn.tree に収録されており,クラス分類であれば sklearn.tree.DecisionTreeClassifier,回帰であれば sklearn.tree.DecisionTreeRegressor を用います.
DecisionTreeClassifier (https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html)
class sklearn.tree.DecisionTreeClassifier(*, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0)| パラメータ名 | 初期値 | 型/取りうる値 | 説明 |
|---|---|---|---|
| criterion | "gini" | "gini", "entropy", "log_loss" | 二分決定木で分割する際の分割条件を指定します. |
| splitter | "best" | "best", "random" | 各ノードでどのような考え方で分割するかを指定します."best" は criterion にて指定した分割条件により算出された最適な値,"random" だとランダムで分割します. |
| max_depth | None | int | 木構造の最大の深さを指定します.None の場合,全てのリーフが純粋になる(全てのクラスが分けられる)まで,または全てのリーフに含まれるサンプルが min_samples_split 未満になるまで計算されます. |
| min_samples_split | 2 | int, float | 内部ノードを分割するために必要なサンプル数の最小値を指定します.int の場合,min_samples_split が最小値になります.float の場合は ceil(min_samples_split * n_samples) が代入されます. |
| min_samples_leaf | 1 | int, float | リーフノードに必要なサンプル数の最小値を指定します.int の場合,min_samples_leaf を最小サンプル数とします.float の場合は ceil(min_samples_split * n_samples) が代入されます. |
| min_weight_fraction_leaf | 0.0 | float | リーフノードに設定される全てのサンプルに対する重みの合計値の最小重み付け割合を指定します. 0.0 の場合はサンプルの重みは等しくなります. |
| max_features | None | int, float, "sqrt", "log2" | 最適な分割を探す際に探索する特徴量の数を指定します.int の場合はこの値を用います.float の場合,max(1, int(max_features * n_features_in_)) が代入されます."sqrt" の場合は sqrt(n_features) が代入されます."log2" の場合は log2(n_features) が代入されます.None の場合は n_features が代入されます. |
| random_state | None | int | 乱数シード値を指定します. |
| max_leaf_nodes | None | int | リーフノードの最大数を指定します.None の場合は上限無しで計算されます. |
| min_impurity_decrease | 0.0 | float | 分割する際にこの値以上の不純度の減少が見られたとき分割します.class_weight が指定された場合,次の重み付き不純度減少関数によって計算されます.N_t / N * (impurity – N_t_R / N_t * right_impurity – N_t_L / N_t * left_impurity). ここで,N は全てのサンプル数,N_t は現在のノードのサンプル数,N_t_L は左側の子ノードのサンプル数,N_t_L は左側の子ノードのサンプル数, |
| class_weight | None | dict, list, "balanced" | クラス毎の重みを定義します.辞書型では {class_label: weight} といったフォーマットで,クラスに関連付けした重みを指定します.出力が3つ以上のクラスであったり,出力自体が複数ある場合は,各カラムのクラス毎に独立した辞書で重みを定義し,リスト型に入れて指定します."balanced" の場合はラベル y の値を用いて入力データのクラス頻度に反比例する重みを n_samples / (n_classes * np.bincount(y)) として計算されます.None の場合はクラス毎の重みはなしで計算します. |
| ccp_alpha | 0.0 | float (>=0) | 木構造の剪定に使用されるパラメータで,ccp_alpha より小さい最大のコストの複雑さを持つサブツリーが選択されるようになります.0.0 の場合は剪定されません. |
DecisionTreeRegressor (https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeRegressor.html)
class sklearn.tree.DecisionTreeRegressor(*, criterion='squared_error', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, ccp_alpha=0.0)| パラメータ名 | 初期値 | 型/取りうる値 | 説明 |
|---|---|---|---|
| criterion | "squared_error" | "squared_error", "friedman_mse", "absolute_error", "poisson" | 二分決定木で分割する際の分割条件を指定します. |
| splitter | "best" | "best", "random" | 各ノードでどのような考え方で分割するかを指定します."best" は criterion にて指定した分割条件により算出された最適な値,"random" だとランダムで分割します. |
| max_depth | None | int | 木構造の最大の深さを指定します.None の場合,全てのリーフが純粋になる(全てのクラスが分けられる)まで,または全てのリーフに含まれるサンプルが min_samples_split 未満になるまで計算されます. |
| min_samples_split | 2 | int, float | 内部ノードを分割するために必要なサンプル数の最小値を指定します.int の場合,min_samples_split が最小値になります.float の場合は ceil(min_samples_split * n_samples) が代入されます. |
| min_samples_leaf | 1 | int, float | リーフノードに必要なサンプル数の最小値を指定します.int の場合,min_samples_leaf を最小サンプル数とします.float の場合は ceil(min_samples_split * n_samples) が代入されます. |
| min_weight_fraction_leaf | 0.0 | float | リーフノードに設定される全てのサンプルに対する重みの合計値の最小重み付け割合を指定します. 0.0 の場合はサンプルの重みは等しくなります. |
| max_features | None | int, float, "sqrt", "log2" | 最適な分割を探す際に探索する特徴量の数を指定します.int の場合はこの値を用います.float の場合,max(1, int(max_features * n_features_in_)) が代入されます."sqrt" の場合は sqrt(n_features) が代入されます."log2" の場合は log2(n_features) が代入されます.None の場合は n_features が代入されます. |
| random_state | None | int | 乱数シード値を指定します. |
| max_leaf_nodes | None | int | リーフノードの最大数を指定します.None の場合は上限無しで計算されます. |
| min_impurity_decrease | 0.0 | float | 分割する際にこの値以上の不純度の減少が見られたとき分割します.class_weight が指定された場合,次の重み付き不純度減少関数によって計算されます.N_t / N * (impurity – N_t_R / N_t * right_impurity – N_t_L / N_t * left_impurity). ここで,N は全てのサンプル数,N_t は現在のノードのサンプル数,N_t_L は左側の子ノードのサンプル数,N_t_L は左側の子ノードのサンプル数, |
| ccp_alpha | 0.0 | float (>=0) | 木構造の剪定に使用されるパラメータで,ccp_alpha より小さい最大のコストの複雑さを持つサブツリーが選択されるようになります.0.0 の場合は剪定されません. |
それでは使っていきましょう.
今回はフリーのデータセットで有名なアヤメ(花)の品種分類データセットの “iris dataset” (https://archive.ics.uci.edu/ml/datasets/Iris) を用います.
このデータセットについて,説明変数が “sepal_length”: がく片の長さ,”sepal_width”: がく片の幅,”petal_length”: 花びらの長さ,”petal_width”: 花びらの幅,目的変数が “species”: アヤメの品種名 とした 150 個のデータで構成されています.
まずは,以下のように,データを読み込みます(インストールされていない場合は “pip install scikit-learn, seaborn” を実行ください).
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
iris = sns.load_dataset(name="iris")
print(iris)
sns.pairplot(data=iris, hue="species")
plt.show()
# sepal_length sepal_width petal_length petal_width species
# 0 5.1 3.5 1.4 0.2 setosa
# 1 4.9 3.0 1.4 0.2 setosa
# 2 4.7 3.2 1.3 0.2 setosa
# 3 4.6 3.1 1.5 0.2 setosa
# 4 5.0 3.6 1.4 0.2 setosa
# .. ... ... ... ... ...
# 145 6.7 3.0 5.2 2.3 virginica
# 146 6.3 2.5 5.0 1.9 virginica
# 147 6.5 3.0 5.2 2.0 virginica
# 148 6.2 3.4 5.4 2.3 virginica
# 149 5.9 3.0 5.1 1.8 virginica
# [150 rows x 5 columns]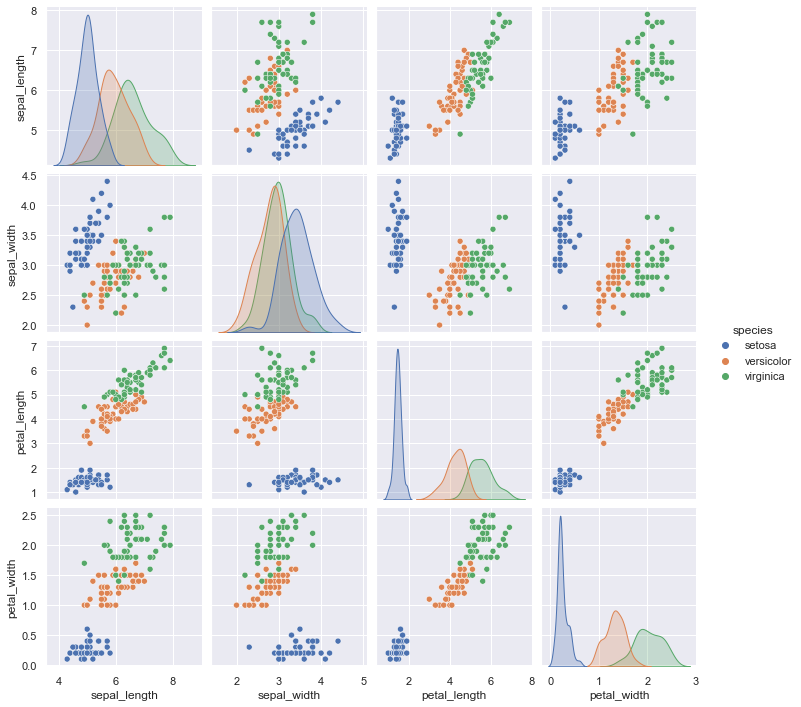
上図から,決定境界を可視化しやすいように2次元の説明変数で分類できそうなデータセットにするため,ここでは “sepal_length” と “sepal_width”,それと目的変数の “species” のみ抜き出して用います.
petal = iris[["petal_length", "petal_width", "species"]]
plt.figure(facecolor="white")
sns.scatterplot(data=petal, x="petal_length", y="petal_width", hue="species")
plt.tight_layout()
plt.show()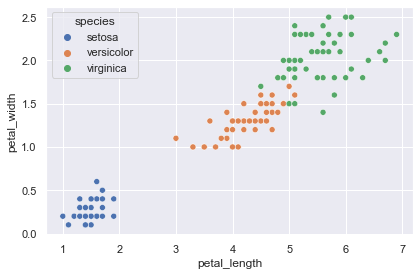
scikit-learn の学習では,ラベルは 0, 1, …, と整数にする必要があります.
このようにラベルなどのカテゴリー変数を数値に変換することをラベルエンコーディング (label encoding) と呼びます.
お手正の変換用の辞書でも構いませんが,scikit-learn にラベルエンコーディングできる関数が用意されていますので,今回は “sklearn.preprocessing.LabelEncoder” を用いて,説明変数を “x”,目的変数を “y” としておきます.
さらに,ついでに学習用と検証用でデータ分割しておきます.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
# 説明変数のカラムだけ抜き出す
x = petal[[v for v in petal.columns if str(v).startswith("petal_")]]
# "species" カラムをラベルエンコーディングして y と置く
encoder = LabelEncoder()
encoder.fit(petal["species"])
y = encoder.transform(petal["species"])
# データ分割
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.2, shuffle=True, random_state=0, stratify=y
)
print(y_train[:10])
# [0 0 0 0 1 0 2 2 1 2]目的変数はクラスなので DecisionTreeClassifierを用います.
また,パラメータについては不純度算出や過学習防止を考慮して criterion=”gini”, max_depth=4 として計算してみましょう.
使い方は scikit-learn なので,いつも通り「モデル定義」→「fit メソッドで学習」→「predict メソッドで推論」です.
from sklearn import tree
model = tree.DecisionTreeClassifier(criterion="gini", max_depth=4, random_state=0)
model.fit(x_train, y_train)
print(model.predict(x_train)[:10])
# [0 0 0 0 1 0 2 2 1 2]上記出力と y_train[:10] の出力が同等なので,うまく学習できていそうですね.
学習に用いていない検証用データセットについても推論し,認識精度を算出してみます.
from sklearn.metrics import accuracy_score
y_pred = model.predict(x_test)
print(f"正解ラベル: {y_test}")
print(f"推論結果: {y_pred}")
print(accuracy_score(y_true=y_test, y_pred=y_pred))
# 正解ラベル: [0 1 0 2 0 1 2 0 0 1 2 1 1 2 1 2 2 1 1 0 0 2 2 2 0 1 1 2 0 0]
# 推論結果: [0 1 0 2 0 1 2 0 0 1 2 1 1 2 1 2 2 1 1 0 0 2 2 1 0 1 1 2 0 0]
# 0.9666666666666667ということで,検証用データセットについて認識精度 96.7 % の推論結果となりました.
実際,どのような決定境界が得られたのか図示してみましょう.
以下の関数は,インプレス出版の「[第2版]Python機械学習プログラミング 達人データサイエンティストによる理論と実践」 (https://book.impress.co.jp/books/1120101017 :リンクは第3版) の p.32 n “plot_decision_regions” 関数を参考にしました.
import warnings
from matplotlib.colors import ListedColormap
def plot_decision_regions(
x: np.ndarray,
y: np.ndarray,
model,
resolution: float = 0.02,
xlabel: str = None,
ylabel: str = None,
figsize: tuple = (6, 5),
encoder: LabelEncoder = None,
) -> None:
# キャスト
x = np.array(x)
y = np.array(y)
# マーカーとカラーマップの準備
markers = ("s", "x", "o", "^", "v")
colors = ("red", "blue", "lightgreen", "gray", "cyan")
cmap = ListedColormap(colors=colors[:len(np.unique(y))])
# 決定境界のプロット
x1_min, x1_max = x[:, 0].min() - 1, x[:, 0].max() + 1
x2_min, x2_max = x[:, 1].min() - 1, x[:, 1].max() + 1
# グリッドポイントの生成
xx1, xx2 = np.meshgrid(
np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution),
)
# 各特徴量を1次元配列に変換して予測を実行
z = model.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
# 予測結果を元のグリッドポイントのデータサイズに変換
z = z.reshape(xx1.shape)
# プロット
plt.figure(figsize=figsize)
# グリッドポイントの等高線のプロット
plt.contourf(xx1, xx2, z, alpha=0.3, cmap=cmap)
# 軸の範囲の設定
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# クラスごとにサンプルをプロット
for idx, label in enumerate(np.unique(y)):
if encoder:
label_name = encoder.inverse_transform([label])[0]
else:
label_name = label
with warnings.catch_warnings():
warnings.simplefilter('ignore')
plt.scatter(
x=x[y==label, 0],
y=x[y==label, 1],
alpha=0.8,
c=colors[idx],
marker=markers[idx],
label=label_name,
edgecolor="black",
)
if xlabel:
plt.xlabel(xlabel)
if ylabel:
plt.ylabel(ylabel)
plt.legend(loc="best")
plt.tight_layout()
plt.show()
plt.clf()
plt.close()print(f"accuracy score: {accuracy_score(y_true=y, y_pred=model.predict(x)):.6f}")
plot_decision_regions(
x=x, y=y, model=model, xlabel="petal_length", ylabel="petal_width", encoder=encoder
)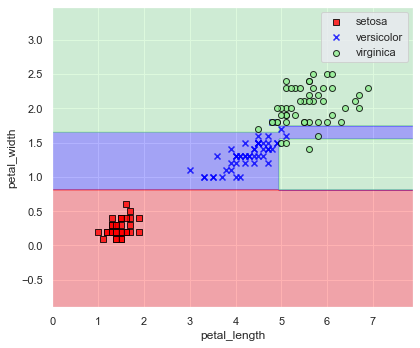
(petal_length, petal_width) = (5, 1.7) あたりは決定境界が怪しいですが,良い感じに品種分割できていますね.
二分決定木は説明変数を2つに分けていくので,上図のように決定境界も上下/左右分割を繰り返して作成されたものになります.
前回の記事 (https://slash-z.com/svm-support-vector-machine/) で linear SVC では全然ダメだったこちらの分布についても決定木でどうなるかを試してみましょう.
まずはデータ生成していきます.
rng = np.random.default_rng(seed=0)
size = 300
# 説明変数
x = rng.normal(size=size*2).reshape((size, 2))
# 目的変数
y = x[:,0]*x[:,1] > 0
fig = plt.figure(facecolor="white")
ax = plt.axes(aspect="equal")
ax.scatter(x[:, 0], x[:, 1], c=y, cmap="coolwarm_r")
ax.set_xlabel("x1")
ax.set_ylabel("x2")
ax.set_xlim(-4, 4)
ax.set_ylim(-4, 4)
fig.tight_layout()
plt.show()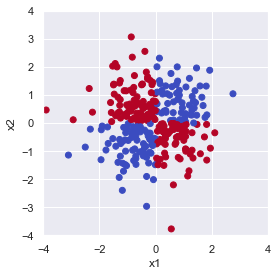
上図は \(x_1 \times x_2\) が 0 より大きくなる点(第1,3象限)を True で青, 0 以下になる点(第2,4象限)を False で赤としてプロットしています.
では,先ほどと同じパラメータの criterion=”gini”, max_depth=4 として決定木で学習してみましょう.
model = tree.DecisionTreeClassifier(criterion="gini", max_depth=4, random_state=0)
model.fit(x, y)
print(f"accuracy score: {accuracy_score(y_true=y, y_pred=model.predict(x)):.6f}")
plot_decision_regions(x=x, y=y, model=model, xlabel="x1", ylabel="x2")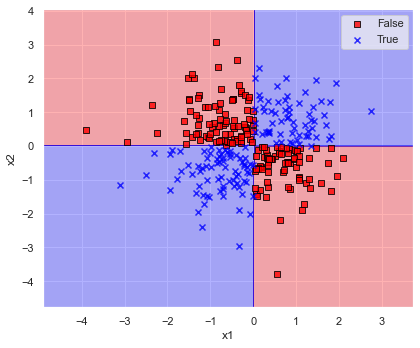
見事にデータを4つの象限で分けることができました.
人の感性とも合致しているので完璧ですね.
演習問題
Q1. ワインデータセットについて,以下を参照して,目的変数であるワインの等級を決定木によって求めてください.
- データ分割は train_test_split にて行い,学習用データは全データの 90 %,データのシャッフルは True としてください(結果に再現性を持たせたい場合は,引数 random_state に任意の数を設定してください)
- データは,以下のコードにて読み込むことができます(データの説明はこちら:https://slash-z.com/matplotlib-first-step/)
from sklearn.datasets import load_wine
df_x, df_y = load_wine(return_X_y=True, as_frame=True)- scikit-learn を用いて分類問題における認識精度を確認するには,以下のようにして算出が可能です.
from sklearn.metrics import accuracy_score
print(accuracy_score(y_true, y_pred))Q2. カリフォルニア住宅価格データセットについて,決定木を用いて以下の手順で住宅価格を予測してみましょう.
- 次のコードでデータ読み込み,学習用/検証用にデータを分割します.
from sklearn.datasets import fetch_california_housing
df_x, df_y = fetch_california_housing(return_X_y=True, as_frame=True)
x_train, x_test, y_train, y_test = train_test_split(
df_x, df_y, test_size=0.25, shuffle=True, random_state=0,
)
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape)- 学習用データ (x_train, y_train) のみを学習し,検証用データ x_test について住宅価格を予測しましょう.
- 上記で予測した住宅価格について,正解の値との絶対平均誤差を算出してみましょう.
以下のコードにて絶対平均誤差が算出できます.
ここで,y_true は正解データの y_test,y_pred には x_test に対するモデルの推論結果を代入してください.
from sklearn.metrics import mean_absolute_error
print(mean_absolute_error(y_true, y_pred))Q3. カルフォルニア大学アーバイン校(UCI)が提供している,手書き数字のデータセット (API: https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html) について,何の数字かを認識してみましょう.データ読み込みは以下のコードを実行します.
from sklearn.datasets import load_digits
# データ読み込み
x, y = load_digits(return_X_y=True)演習問題の解答
Q1. ワインデータセットについて,以下を参照して,目的変数であるワインの等級を決定木によって求めてください.
import numpy as np
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.metrics import accuracy_score
from sklearn import tree
from sklearn.model_selection import train_test_split
# データ読み込み
df_x, df_y = load_wine(return_X_y=True, as_frame=True)
# データ分割
x_train, x_test, y_train, y_test = train_test_split(
df_x, df_y, test_size=0.1, shuffle=True, random_state=0, stratify=df_y
)# 学習/推論
model = tree.DecisionTreeClassifier(criterion="gini", max_depth=4, random_state=0)
model.fit(x_train, y_train)
pred = model.predict(df_x)
# 分類精度算出
print(accuracy_score(y_true=df_y, y_pred=pred))
# 1.0Q2. カリフォルニア住宅価格データセットについて,SVR を用いて以下の手順で住宅価格を予測してみましょう.
from sklearn.datasets import fetch_california_housing
from sklearn.metrics import mean_absolute_error
# データ読み込み/分割
df_x, df_y = fetch_california_housing(return_X_y=True, as_frame=True)
df_x = (df_x - df_x.min()) / (df_x.max() - df_x.min())
x_train, x_test, y_train, y_test = train_test_split(
df_x, df_y, test_size=0.25, shuffle=True, random_state=0,
)model = tree.DecisionTreeRegressor(criterion="squared_error", max_depth=10, random_state=0)
model.fit(x_train, y_train)
pred = model.predict(x_test)
print(mean_absolute_error(y_true=y_test, y_pred=pred))
# 0.4326357557565234Q3. カルフォルニア大学アーバイン校(UCI)が提供している,手書き数字のデータセット (API: https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html) について,何の数字かを認識してみましょう.データ読み込みは以下のコードを実行します.
from sklearn.datasets import load_digits
# データ読み込み
x, y = load_digits(return_X_y=True)x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.1, shuffle=True, random_state=0, stratify=y
)
model = tree.DecisionTreeClassifier(criterion="gini", max_depth=20, random_state=0)
model.fit(x_train, y_train)
pred = model.predict(x)
print(accuracy_score(y_true=y, y_pred=pred))
# 0.9855314412910406機械学習の勉強でおすすめの本
“Python機械学習プログラミング 達人データサイエンティストによる理論と実践” は 500 ページ超もあり,理論や実装についてしっかり書かれているため,体系的・網羅的に学習できます.
しかしながら超大作であるため,初学者が全部を一から読み進めて行くという使い方だと,よほどの根気がなければ挫折すると思います.
また,数式もちゃんと書かれてはいるのですが,基礎的な解析学や線形代数学などの知識があること前提に書かれていますので,大学のときの教科書や参考書,web 記事なども参考にする必要があります.
従いまして,見たいところだけを随時見たり,ある程度身についてきてからハンドブック的に用いることを推奨します.
筆者は,こちらの第2版を購入しており,今もハンドブック的な役割で使っています.
数学の知識について,個人的には,演習問題もついててお得な,以下の書籍をハンドブック的に参考にすることが多いです.
深く内容を見返したい場合は,大学のときの教科書や参考書を見ています.


コメント