
お仕事お疲れ様です.
こんなことは経験ありませんか?
「現場や顧客から分析を依頼された .csv データが数 GByte 超で,excel では開けないし,普通に読みこむとメモリエラーで詰んだ….」
「センサーを放ったらかしてデータを取得し続けていたら,いつの間にか .csv データが肥大化していた」
など,予期せぬ巨大 .csv ファイルがこの世に生まれ,それを処理する人が居るわけであり,そしてそれはあなたかもしれません.
上記のことを想定し,今回は .csv / .parquet / .pkl / .sqlite3 など色々なファイル形式で,かつ,メモリ消費を少なく抑えて保存していきます.
結論
- .parquet で保存・・・・I/O 速度,容量ともに優秀.pyarrow で .csv と同様に一部ずつ読み込むことができる.
- .pkl で保存・・・・I/O 速度,容量ともに優秀.型やオブジェクトが保存可能.
- .sqlite3 で保存・・・・.parquet / .pkl よりも速度や容量は劣るが,.csv よりは遥かに優れているし,SQL が使えるためデータエンジニアリング的に便利.
トイデータとなる .csv ファイル生成 and .csv / .parquet 保存
まずは,トイデータとして保存容量が数 GB オーダーの .csv を作成していきます.
import random
from pathlib import Path
from time import perf_counter
import numpy as np
import pandas as pdテキトーに,2022/01/01 から 2023/12/31 の期間で 1 秒刻みのデータテーブルを以下で作成.
rng = np.random.default_rng(seed=0)
random.seed(0)
df = (
pd.DataFrame(
data={
"time_stamp": pd.date_range(start="2022-01-01", end="2023-12-31", freq="s"),
# "time_stamp": pd.date_range(start="2022-01-01", end="2023-12-31", freq="d"),
}
)
.reset_index()
.rename(columns={"index": "id"})
)
df.index = df["time_stamp"]
df.drop(columns=["time_stamp"], inplace=True)
df["status"] = [random.choice(["a", "b", "c", None]) for _ in range(df.__len__())]
df["temperature"] = 20 + np.sin(np.arange(0, df.__len__()) / np.pi) * rng.random(
size=df.__len__()
)
df["humidity"] = 50 + 3 * np.cos(np.arange(0, df.__len__()) / np.pi) * rng.random(
size=df.__len__()
)
df["ax"] = (
1 * np.sin(np.arange(0, df.__len__()) / 10 * np.pi) * rng.random(size=df.__len__())
)
df["ay"] = (
2 * np.cos(np.arange(0, df.__len__()) / 10 * np.pi) * rng.random(size=df.__len__())
)
df["az"] = (
3 * np.cos(np.arange(0, df.__len__()) / 10 * np.pi) * rng.random(size=df.__len__())
)
df["gx"] = (
0.3
* np.sin(np.arange(0, df.__len__()) / 100 * np.pi)
* rng.random(size=df.__len__())
)
df["gy"] = (
0.2
* np.cos(np.arange(0, df.__len__()) / 100 * np.pi)
* rng.random(size=df.__len__())
)
df["gz"] = (
0.1
* np.cos(np.arange(0, df.__len__()) / 100 * np.pi)
* rng.random(size=df.__len__())
)df.info()
# <class 'pandas.core.frame.DataFrame'>
# DatetimeIndex: 62985601 entries, 2022-01-01 00:00:00 to 2023-12-31 00:00:00
# Data columns (total 10 columns):
# # Column Dtype
# --- ------ -----
# 0 id int64
# 1 status object
# 2 temperature float64
# 3 humidity float64
# 4 ax float64
# 5 ay float64
# 6 az float64
# 7 gx float64
# 8 gy float64
# 9 gz float64
# dtypes: float64(8), int64(1), object(1)
# memory usage: 5.2+ GBメモリサイズで 5.2 GB の pandas.DataFrame ができました.
とりあえずこいつを時間を測りながら .csv / .parquet /.pkl 化してみましょう.
(parquet ファイルは列ごとにデータを整理して保存することにより高い圧縮率と I/O 速度が得られるデータ形式で,pickle ファイルも高い圧縮率と I/O 速度が得られますが,こちらはバイナリファイルで,型やオブジェクトが保存できます.)
t_start = perf_counter()
df.to_csv("../data/large_table.csv", index=False)
print(f"elapsed: {perf_counter() - t_start}")
# elapsed: 1090.711631446t_start = perf_counter()
df.to_parquet("../data/large_table.parquet", index=None)
print(f"elapsed: {perf_counter() - t_start}")
# elapsed: 46.29157750000013t_start = perf_counter()
df.to_pickle("../data/large_table.pkl")
print(f"elapsed: {perf_counter() - t_start}")
# elapsed: 45.324502749999965.csv 保存よりも .parquet / .pkl 保存のほうが 22 倍高速に保存できる結果となりました.

ファイル容量については .parquet < .pkl < .csv 保存の順で優秀で,.csv の半分以下まで抑えられています.
作成した .csv を .sqlite3 に変換
今度は,作成した .csv を .sqlite3 に変換します.
import gc
import math
import resource
import sqlite3
from pathlib import Path
import numpy as np
import pandas as pd
import pyarrow as pa
from pyarrow.parquet import ParquetFile
from tqdm import tqdmハイスペック PC やクラウド環境であればメモリを気にする必要はありませんが,今回はメモリ 16 GB で,色々なアプリケーション立ち上げながら業務していて,残り 6 GB 使える状況を想定します.
ということで,メモリ上限を次で 6 GB に設定します.
# メモリ上限を 6 GB に設定
resource.setrlimit(resource.RLIMIT_DATA, (6 * 2**30, -1))
resource.getrlimit(resource.RLIMIT_DATA)
# (6442450944, -1)pandas.read_csv でシンプルに読み込むと,以下の通りメモリエラーでカーネルがクラッシュします.
# df = pd.read_csv("../data/large_table.csv")
# ↓そのまま実行した結果
# 現在のセルまたは前のセルでコードを実行中に、カーネルがクラッシュしました。これの対策として,pandas.read_csv() のオプショナル引数である chunksize を int で指定することで,この chunksize 分のイテレータとして返します.
試しに chuksize=100,000 とした場合の dataframe がどのくらいのメモリを要するか見てます.
for i, df_i in enumerate(pd.read_csv("../data/large_table.csv", chunksize=100_000)):
print(df_i.index[-1])
if i >= 2:
break
# 99999
# 199999
# 299999df_i.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 100000 entries, 200000 to 299999
# Data columns (total 10 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 id 100000 non-null int64
# 1 status 74950 non-null object
# 2 temperature 100000 non-null float64
# 3 humidity 100000 non-null float64
# 4 ax 100000 non-null float64
# 5 ay 100000 non-null float64
# 6 az 100000 non-null float64
# 7 gx 100000 non-null float64
# 8 gy 100000 non-null float64
# 9 gz 100000 non-null float64
# dtypes: float64(8), int64(1), object(1)
# memory usage: 7.6+ MBそのまま読み込んだ場合は,推定 6 GB 以上でしたが,chunksize=100,000 とした場合は 7.6 MB 程度とかなり省メモリになっています.
これを用いて chunksize ごとに .sqlite3 化していきますが,データ量が大きいことから保存処理が進んでいるのかどうか心配になることから tqdm (進捗率表示ライブラリ)を用いるため,まずは行数と chunksize にあった繰り返し回数を取得します.
chunksize = 1_000_000
df_iter = pd.read_csv("../data/large_table.csv", chunksize=chunksize)
num_records = 0
while True:
df_i = next(df_iter, None)
if df_i is None:
break
num_records += df_i.__len__()
del df_i
gc.collect()
print(num_records)
# 62985601num_iter = math.ceil(num_records / chunksize)
print(num_iter)
# 63この繰り返し回数: num_iter を用いて以下で .sqlite3 化していきます.
お好みで df_i.to_sql の前に型変換などの処理を追加しても良いでしょう.
database_path = Path("../data/large_table.sqlite3")
database_path.unlink(missing_ok=True)
con = sqlite3.connect(database=database_path)
table_name = "test"
# tmp.to_sql(name=table_name, con=con, if_exists="append")
df_iter = pd.read_csv("../data/large_table.csv", chunksize=chunksize)
for _ in tqdm(range(num_iter)):
df_i = next(df_iter, None)
if df_i is None:
break
df_i.to_sql(name=table_name, con=con, if_exists="append")
del df_i
gc.collect()
con.close()
# 100%|██████████| 63/63 [08:41<00:00, 8.27s/it]結果として .sqlite3 保存した場合のサイズは 6.69 GB で,8 min 41 s かかりました.
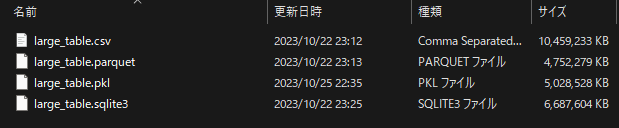
以上から,
- .parquet で保存・・・・I/O 速度,容量ともに優秀.pyarrow で .csv と同様に一部ずつ読み込むことができる.
- .pkl で保存・・・・I/O 速度,容量ともに優秀.型やオブジェクトが保存可能.
- .sqlite3 で保存・・・・.parquet よりも速度や容量は劣るが,.csv よりは遥かに優れているし,SQL が使えるためデータエンジニアリング的に便利.
という特徴があり,単にファイル保存したいだけなら .parquet 保存,データを SQL からいじりたい場合や追加/修正が発生する場合は .sqlite3 保存が好ましいでしょう.


コメント