
日本のデスクワーカーにおいて,Microsoft 社の表計算ソフトである excel は,ほとんどの方が業務で用いられる避けて通れないツールだと思われます(excel 以外の表計算ソフトを用いる場合もあると思います).
excel は GUI を用いた操作性が良く,簡易的に数式や条件式を組んで表計算ができたり,色付けや罫線,図やグラフを入れることができたりして,計算やその可視化,台帳,または用紙やポスターにいたるまで,何でもできてしまいます.
更には,細かいところに手を届かせるように,マクロだったり VBA を用いることができますよね.
実は「何でもできる」というのがかえって落とし穴で,表計算ソフトである excel を,表計算を全く使わないような手順書や報告書に用いているケースも多く見られます.
(特に問題なのが,印刷して手書きすることを前提に作られた excel シートを,そのままの形式で台帳として用いられることで,ご丁寧に罫線をきれいに使い分けているとコピペしたときにその体裁が崩れるので修正する工数が発生したり,セルの結合とかがあると後々プログラミングでデータを吸い出すのも面倒です.)
愚痴はこのくらいにして,なぜこれほどまでに必須のツールになっているか考えると,やはり,誰でも簡単に使える = 他の人が作ったファイルを編集して流用しやすい,というところだと思います.
しかしながら,他の強力なライブラリが使えたりといった柔軟性や,処理の軽快さ,パワフルな計算能力というのは,プログラミングに軍配が上がると言えます.
そのプログラミング言語の中でも Python はテーブルデータの操作に特化したライブラリの pandas があったり,excel を操作するための openpyxl というライブラリがあったり,GUI 操作を自動化させるための PyAutoGUI があったり,そもそもの言語仕様として簡便な記述によって動作するため,Python を学べば学ぶほど,VBA や excel にて計算を行ったりグラフを作成するといったことから離れていくと思われます.
とはいえ,サラリーマンたるもの,上司や他部署の関係者から「資料やデータを直したいから計算書を見して」などと言われたときに,「excel なんて触りませんよ」と言ってしまうのは,”孤高” や “尖っている” ではなく “思いやる気持ちが足りていない” などと負の印象を持たれることでしょう.
ですので,今回は,慣れ親しんできたであろう Python を用いて,表計算ソフトでは煩雑と思われる処理を高速に半自動で行わせ,後で Python が分からない他者が理解/処理できるように excel にて出力することを目標に,その手順について例を上げて紹介していきます.
今回のコードは,こちらの github にも載せています.
excel 操作に必要なライブラリのインストール
使い方にもよりますが,基本的には excel 自体の操作と,Python 側でテーブルデータの操作や配列の演算などを実行することを想定すると,以下のライブラリを pip install すれば良いでしょう.
- pandas:テーブルデータ操作に強いライブラリ
- openpyxl:excel の操作全般を行うことができるライブラリ
- numpy:数学演算や行列計算などを C 言語実装によりパワフルに行うことができるライブラリ
- xlrd, xlwt:excel を読み書きするときに裏で用いられるライブラリ(コードの中で import して使うということは無いと思います)
以下でインストールしましょう.
pip install pandas openpyxl numpy xlrd xlwt
上記にて会社プロキシだったりオフライン環境下であることが原因でインストールできなかった場合は,以下の記事が参考になるでしょう.

また,今回は numpy と pandas を用いますが,以下の記事が参考になるでしょう.
書き込み・読み込みは pandas / openpyxl
excel ファイルへの書き込み,及び excel ファイルの読み込みは,pandas / openpyxl を用いることで可能です.
まずは,書き込む用のデータを,例えば以下にて生成します.
import pandas as pd
import numpy as np
df_src = pd.DataFrame(data=np.arange(0, 4*5).reshape(4, 5))
print(df_src)
# 0 1 2 3 4
# 0 0 1 2 3 4
# 1 5 6 7 8 9
# 2 10 11 12 13 14
# 3 15 16 17 18 19pandas では,pandas.DataFrame オブジェクトに対して .to_excel メソッドにより excel 出力が可能です.
df_src.to_excel("./data_00.xlsx")上で作成した data_00.xlsx について,早速開いてみましょう.
もちろん,excel が無い方は,無料でインストール不要な google のスプレッドシートなどでも問題ありません(僕も個人持ち PC には MS Office が入っていなく,購入時に付属していた KINGSOFT の WPS Spredsheets にて以下動作確認しています).
手持ちのソフトの関係上なんか緑色に塗られていますが,以下のような出力が得られたと思います.
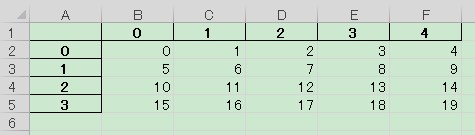
インデックスとカラムの先頭が太字で罫線有りになっていますが,修正方法については後回しにします.
.to_excel にて行番号が不要であれば,引数 index に False を渡すことでこの列を無視できます.
df_src.to_excel("./data_01.xlsx", index=False)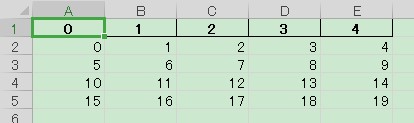
また,引数でシート名やカラム名なしなどいろいろ設定が可能ですが,今回は割愛します.
作成した .xlsx ファイルは,pandas.read_excel にて読み込むことができます (https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_excel.html).
tmp = pd.read_excel("./data_01.xlsx")
print(tmp)
# 0 1 2 3 4
# 0 0 1 2 3 4
# 1 5 6 7 8 9
# 2 10 11 12 13 14
# 3 15 16 17 18 19非常に簡単ですね.
これまた,読み込むシートを指定できたり,読み込み始める先頭を指定できたりといった色々な操作を,引数を与えることで可能となっています (https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html).
(pandas を用いた複数シートへの保存は後述します)
次に openpyxl による excel ファイルの読み書きです.
基本的には openpyxl の workbook という excel ファイル全体となるオブジェクトを作成し,この属性の sheet というシートの中の cell であったり色んな属性やメソッドを操作していく使い方です.
まずはインポートしましょう.
よく使うのは Workbook クラスなので,はじめにこれをインポートしています.
openpyxl で excel ファイルを出力してみましょう.
流れとしては Workbook オブジェクトを定義し,これについて情報を付加していき,.save メソッドにてファイル出力します.
from openpyxl import Workbook
# Workbook オブジェクトを定義
wb = Workbook()
# sheet オブジェクトをインスタンス化 (Workbook が定義された時点で "sheet" というシートが作成される)
ws = wb.active
# もとからある "sheet" の名前を変更
ws.title = "hello"
# 番地 A1 に world を記入
ws["A1"] = "world"
# 保存
wb.save("./data_02.xlsx")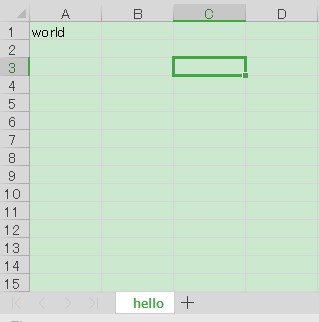
出力されたファイルを見ると,hello という名前のシートの A1 に world という文字列が記載されています.
インスタンス化した Workbook オブジェクトについて,変な操作を加えたくない場合は,いったん .close() しておきましょう.
wb.close()次に,この出力を openpyxl で読み込んでみましょう.
openpyxl の load_workbook を用います.
from openpyxl import load_workbook
wb = load_workbook("./data_02.xlsx")
print(wb.sheetnames)
# ['hello']これだけです.
2 行目のコードは,ブックのシート名称をリストにて取得しています.
基本操作:シートの追加
シートを追加する場合は,Workbook オブジェクトの .create_sheet メソッドを用いたり,pandas.ExcelWriter オブジェクトを使って pandas.DataFrame.to_excel(pandas.ExcelWriter({file_path}), sheet_name={sheet_name}, mode=”a”) で追加するという複数の手段があります.
このとき,pandas.ExcelWriter(*, mode=”a”) という風に,追加する場合は mode=”a” とすることに注意しましょう.
# Workbook 定義
wb = Workbook()
# シートのインスタンス化
ws = wb.active
# 適当に記入 (数式は文字列で記入)
ws["a1"] = 0
ws["b3"] = "openpyxl"
ws["c2"] = "=sum(a2:a4)"
# セルに対する操作は worksheet.cell を用い,引数 row, column に行番号と列番号を渡します
# 上記で定義したセルに値を代入したい場合は,.value 属性に対して値を代入します
ws.cell(row=8, column=5).value = "ws.cell(row=8, column=5)"
# 2 枚目以降のシートは .create_sheet にて追加
ws2 = wb.create_sheet(title="2nd")
# 適当に記入
for i in range(5):
ws2[f"b{i+1}"] = i
# 保存
wb.save("./data_03.xlsx")
# シート名を表示
print(wb.sheetnames)
# pandas でシートを追加 (mode="a" とすることで,既存ファイルに追記)
with pd.ExcelWriter("./data_03.xlsx", mode="a") as w:
df_src.to_excel(w, sheet_name="3", index=False)
df_src.describe().to_excel(w, sheet_name="4枚目")
# シート名称を表示(pandas を用いた.pandas.ExcelFile で openpyxl の Workbook のようにも使えます)
print(pd.ExcelFile("./data_03.xlsx").sheet_names)
# ['Sheet', '2nd']
# ['Sheet', '2nd', '3', '4枚目']./data_03.xlsx を開くと,各シートが以下のようになります.


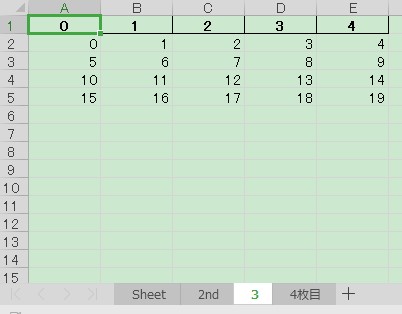
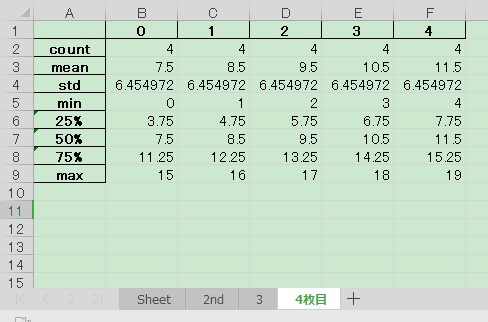
pandas でシートを指定して読み込み
pandas.read_excel にて,引数 sheet_name に文字列で名称を指定するか,何枚目のシートかを int で指定することにより,任意のシートの情報を取得することが可能です.
print(pd.read_excel("./data_03.xlsx", sheet_name="3"))
# 0 1 2 3 4
# 0 0 1 2 3 4
# 1 5 6 7 8 9
# 2 10 11 12 13 14
# 3 15 16 17 18 19
print(pd.read_excel("./data_03.xlsx", sheet_name=3))
# Unnamed: 0 0 1 2 3 4
# 0 count 4.000000 4.000000 4.000000 4.000000 4.000000
# 1 mean 7.500000 8.500000 9.500000 10.500000 11.500000
# 2 std 6.454972 6.454972 6.454972 6.454972 6.454972
# 3 min 0.000000 1.000000 2.000000 3.000000 4.000000
# 4 25% 3.750000 4.750000 5.750000 6.750000 7.750000
# 5 50% 7.500000 8.500000 9.500000 10.500000 11.500000
# 6 75% 11.250000 12.250000 13.250000 14.250000 15.250000
# 7 max 15.000000 16.000000 17.000000 18.000000 19.000000上記の例で,上段は “3” というシートが 3 枚目にあってそれを読み込んでいるのと,下段は 0 から数えて 3 は 4 つめなので 4 枚目のシートを読み込んでいます.
シート名称で指定する場合に名称一覧が必要になりますが,これについては,pandas.ExcelFile(*).sheet_names で確認するのが手っ取り早いでしょう.
print(pd.ExcelFile("./data_03.xlsx").sheet_names)
# ['Sheet', '2nd', '3', '4枚目'].xlsx ファイル全体をざっと概観したい場合は,次のように for を用いて表示しても良いかもしれません.
重量級な .xlsx であれば,以下最終行の read_excel() の後に .head(3) とか .tail(3) とかするのも良いでしょう.
file_path = "./data_03.xlsx"
names = pd.ExcelFile(file_path).sheet_names
for name in names:
print(f"\n*** sheet: {name}")
print(pd.read_excel(file_path, sheet_name=name))
#
# *** sheet: Sheet
# 0 Unnamed: 1 Unnamed: 2 Unnamed: 3 Unnamed: 4
# 0 NaN NaN NaN NaN NaN
# 1 NaN openpyxl NaN NaN NaN
# 2 NaN NaN NaN NaN NaN
# 3 NaN NaN NaN NaN NaN
# 4 NaN NaN NaN NaN NaN
# 5 NaN NaN NaN NaN NaN
# 6 NaN NaN NaN NaN ws.cell(row=8, column=5)
#
# *** sheet: 2nd
# Unnamed: 0 0
# 0 NaN 1
# 1 NaN 2
# 2 NaN 3
# 3 NaN 4
#
# *** sheet: 3
# 0 1 2 3 4
# 0 0 1 2 3 4
# 1 5 6 7 8 9
# 2 10 11 12 13 14
# 3 15 16 17 18 19
#
# *** sheet: 4枚目
# Unnamed: 0 0 1 2 3 4
# 0 count 4.000000 4.000000 4.000000 4.000000 4.000000
# 1 mean 7.500000 8.500000 9.500000 10.500000 11.500000
# 2 std 6.454972 6.454972 6.454972 6.454972 6.454972
# 3 min 0.000000 1.000000 2.000000 3.000000 4.000000
# 4 25% 3.750000 4.750000 5.750000 6.750000 7.750000
# 5 50% 7.500000 8.500000 9.500000 10.500000 11.500000
# 6 75% 11.250000 12.250000 13.250000 14.250000 15.250000
# 7 max 15.000000 16.000000 17.000000 18.000000 19.000000処理速度としては,excel を立ち上げている時間内で出力されるほど爆速です.
注意として,巨大な .csv ファイルを読み込むのと違って,巨大な .xlsx ファイルを読み込む場合には時間がかかることがあります.
あとは,シート内に表が複数点在しているような素直でないシートの場合は,上記では満足に可視化することはできないかもしれません.
pandas.to_excel で先頭が太字・罫線になることの修正
pandas.to_excel にて容易にシート作成ができましたが,先頭のセルが勝手に太字になったり,罫線が付いたりすることについて好みでない場合は,cell の font / border を適用することで解決できます.
font, border 属性には他にも色々設定できます.
以下でやってみます.
from openpyxl import styles
# 任意の font 属性を定義
font_normal = styles.Font(
name="Arial", size=11, bold=False, italic=False, underline="none", color="FF000000"
)
# 任意の border 属性を定義
border_normal = styles.Border(left=None, right=None, top=None, bottom=None, diagonal=None)
# 上記を cell の font / border 属性にそれぞれ代入します
# ファイル名定義
f_path = "./data_04.xlsx"
# ファイル作成と保存
pd.DataFrame(data={"aaa": range(3), "bb": range(3)}).to_excel(f_path, index=False, sheet_name="01")
# openpyxl で読み込み
wb = load_workbook(f_path)
# シート "01" をインスタンス化
ws = wb["01"]
# cell の font / border 属性にそれぞれ代入
ws.cell(row=1, column=1).font = font_normal
ws.cell(row=1, column=1).border = border_normal
# 保存
wb.save(f_path)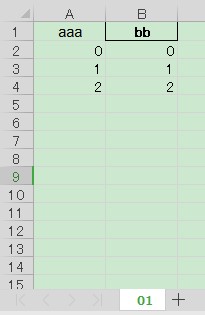
A1 において,指定したフォントと罫線になっています.
しかし,それ以外は設定が反映されていません.
こういう場合は,値が入力されている範囲を取得し,全セルに対して font / border に代入していきましょう.
値があるセルの行・列番号の最大・最小値は,sheet 属性の max_row, min_row, max_column, min_column にてそれぞれ取得できます.
# "./data_04.xlsx" を読み込んでシート "01" をインスタンス化
wb = load_workbook("./data_04.xlsx")
ws = wb["01"]
# 値があるセルの行・列番号の最大・最小値を取得
min_row, max_row = ws.min_row, ws.max_row
min_column, max_column = ws.min_column, ws.max_column
# 上記を用いて for 文で cell 一つずつに style を代入
for row in range(min_row, max_row + 1):
for column in range(min_column, max_column + 1):
ws.cell(row=row, column=column).font = font_normal
ws.cell(row=row, column=column).border = border_normal
# 保存
wb.save("./data_05.xlsx")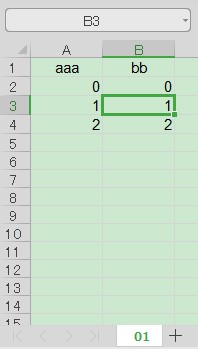
これですべてのセルのフォント・罫線が設定できるようになりました.
行高さ/列幅の修正
カラム名や要素の値が長いとセルからはみ出してしまうので,行の高さだったり列の幅を指定したい場合もあると思います.
そういうときは,sheet オブジェクトの row_dimensions[行名称].height / column_dimensions[列名称].width に値を代入することで調整できます.
ここで,注意としては列を名称にて指定する必要が有ることです.
# "./data_05.xlsx" を読み込んでシート "01" をインスタンス化
wb = load_workbook("./data_05.xlsx")
ws = wb["01"]
# 値があるセルの行・列番号の最大・最小値を取得
min_row, max_row = ws.min_row, ws.max_row
min_column, max_column = ws.min_column, ws.max_column
# 値がある列の名称を取得
columns = [ws.cell(row=min_row, column=v).column_letter for v in range(min_row, max_row + 1)]
# 上記を用いて for 文で行の高さ・列の幅を行・列ごとに代入していきます
for row in range(min_row, max_row + 1):
ws.row_dimensions[row].height = 15
for column in columns:
ws.column_dimensions[column].width = 15
# 保存
wb.save("./data_06.xlsx")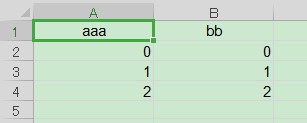
excel 上にグラフを作成
Python でグラフ作成というと matplotlib や seaborn,plotly など非常に使いやすいライブラリがありますが,他者と共有して後に GUI 操作でグラフを修正したい場合などは,やはり excel 上でグラふをプロットしたくなることでしょう.
もちろん,そんなことも openpyxl を用いれば可能です(少々面倒でありますが).
例として,以下に 2 周期分の sin 波の散布図 (openpyxl.chart.ScatterChart) と元データを .xlsx 出力してみます.
from openpyxl.chart import ScatterChart, Series, Reference
# ブックとシート定義
wb = Workbook()
ws = wb.active
# sin 波の x / y 軸を定義
dt = np.pi * 0.01
t = np.arange(0, 2 * 2 * np.pi + dt, dt)
sin_t = np.sin(t)
# sin 波をシートに記入
for i in range(len(t)):
ws.cell(row=i+1, column=1).value = t[i]
ws.cell(row=i+1, column=2).value = sin_t[i]
# # プロット
# ScatterChart をインスタンス化し,これに追加していきます
chart = ScatterChart()
# タイトルを設定
chart.title = "sin 波"
# グラフの大きさを指定
chart.height = 8
chart.width = 13
# x / y 軸名称を設定
chart.x_axis.title = "信号"
chart.y_axis.title = "経過時間 [s]"
# 凡例
chart.legend = None
# プロットで参照するセルを定義
x = Reference(worksheet=ws, min_col=1, min_row=1, max_row=len(t))
y = Reference(worksheet=ws, min_col=2, min_row=1, max_row=len(t))
# 参照するセルを Series に渡し,これを chart.series に入れる
series = Series(y, x, title_from_data=True)
chart.series.append(series)
# プロット(anchor にて左上の点を指定)
ws.add_chart(chart=chart, anchor="d2")
# 保存
wb.save("./data_07.xlsx")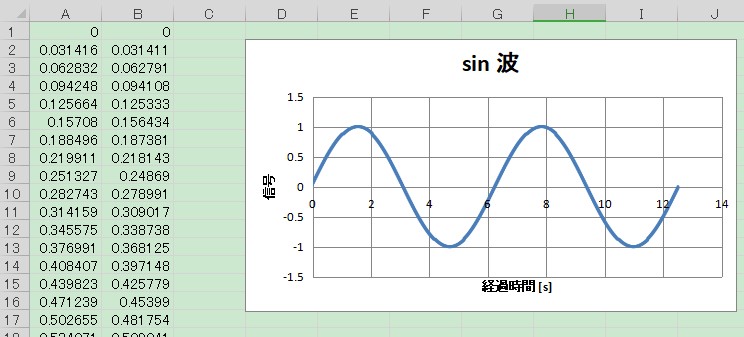
上図のようにプロットできたと思います.
流れとしては,pandas.DataFrame.to_excel() し,これを openpyxl にて読み込んで訂正を整え,最後にグラフを貼るというふうにすると,一番工数が少なく済むでしょう.
Python を用いた自動化についてのオススメの書籍
以下書籍は,「退屈なことは Python にやらせよう」というタイトルの通り,日常の事務作業におけるデータシート作成,図形描画,メール操作,あるいはGUI操作など決まった処理をPythonを用いて自動化させようという書籍です.
自動化処理の実装だけでなくPythonの基礎や各ライブラリの説明など詳しく書かれているため,「Pythonで何かの処理を自動化させたい」という方に特にオススメです.
※ 「ノンプログラマー」というフレーズがありますが,もちろんプログラミングはします.
コメント